
1/7
@AIfeedFyi
Major developments in AI last week.
1. Grok Imagine with voice input.
2. ChatGPT introduces branching.
3. Google drops EmbeddingGemma.
4. Kimi K2 update.
5. Alibaba Qwen3-Max-Preview.
Full breakdown of the AI feed below ↓
2/7
@AIfeedFyi
1. Elon Musk xAI announces Grok Imagine now accepts speech input.
Users can now generate animated clips directly from voice prompts.
[Quoted tweet]
Grok video now has speech.
Also, major upgrade to image/video generation in training. Should be ready in ~2 weeks.
3/7
@AIfeedFyi
2. ChatGPT adds the ability to branch a conversation, you can spin off new threads without losing the original.
Nice feature for testing different directions in parallel.
[Quoted tweet]
By popular request: you can now branch conversations in ChatGPT, letting you more easily explore different directions without losing your original thread.
Available now to logged-in users on web.

4/7
@AIfeedFyi
3. Google introduces EmbeddingGemma.
→ 308M parameter embedding model built for on-device AI.
→ Delivers SOTA performance while being small and efficient enough to run anywhere.
https://video.twimg.com/amplify_video/1963634357878333440/vid/avc1/1920x1080/8j44A5DJKjMWnGIA.mp4
5/7
@AIfeedFyi
4. Moonshot AI update Kimi K2-0905
→ Better coding (front-end & tool use).
→ 256k token context window.
[Quoted tweet]
Kimi K2-0905 update
- Enhanced coding capabilities, esp. front-end & tool-calling
- Context length extended to 256k tokens
- Improved integration with various agent scaffolds (e.g., Claude Code, Roo Code, etc)
 Weights & code: huggingface.co/moonshotai/Ki…
Weights & code: huggingface.co/moonshotai/Ki…
 Chat with new Kimi K2 on: kimi.com
Chat with new Kimi K2 on: kimi.com
 ️ For 60–100 TPS + guaranteed 100% tool-call accuracy, try our turbo API: platform.moonshot.ai
️ For 60–100 TPS + guaranteed 100% tool-call accuracy, try our turbo API: platform.moonshot.ai

6/7
@AIfeedFyi
5. Alibaba rolls out Qwen3-Max-Preview.
→ Biggest model yet, with over 1 trillion parameters.
→ Better in reasoning, code generation, and conversation over past Qwen releases.
[Quoted tweet]
Big news: Introducing Qwen3-Max-Preview (Instruct) — our biggest model yet, with over 1 trillion parameters!
Now available via Qwen Chat & Alibaba Cloud API.
Benchmarks show it beats our previous best, Qwen3-235B-A22B-2507. Internal tests + early user feedback confirm: stronger performance, broader knowledge, better at conversations, agentic tasks & instruction following.
Scaling works — and the official release will surprise you even more. Stay tuned!
Qwen Chat: chat.qwen.ai/
Alibaba Cloud API: modelstudio.console.alibabac…

7/7
@AIfeedFyi
Explore http://aifeed.fyi and follow us @AIfeedFyi for full AI signals, breakdowns, and everything happening in AI right now.
/search?q=#AIfeed
@AIfeedFyi
Major developments in AI last week.
1. Grok Imagine with voice input.
2. ChatGPT introduces branching.
3. Google drops EmbeddingGemma.
4. Kimi K2 update.
5. Alibaba Qwen3-Max-Preview.
Full breakdown of the AI feed below ↓
2/7
@AIfeedFyi
1. Elon Musk xAI announces Grok Imagine now accepts speech input.
Users can now generate animated clips directly from voice prompts.
[Quoted tweet]
Grok video now has speech.
Also, major upgrade to image/video generation in training. Should be ready in ~2 weeks.
3/7
@AIfeedFyi
2. ChatGPT adds the ability to branch a conversation, you can spin off new threads without losing the original.
Nice feature for testing different directions in parallel.
[Quoted tweet]
By popular request: you can now branch conversations in ChatGPT, letting you more easily explore different directions without losing your original thread.
Available now to logged-in users on web.
4/7
@AIfeedFyi
3. Google introduces EmbeddingGemma.
→ 308M parameter embedding model built for on-device AI.
→ Delivers SOTA performance while being small and efficient enough to run anywhere.
https://video.twimg.com/amplify_video/1963634357878333440/vid/avc1/1920x1080/8j44A5DJKjMWnGIA.mp4
5/7
@AIfeedFyi
4. Moonshot AI update Kimi K2-0905
→ Better coding (front-end & tool use).
→ 256k token context window.
[Quoted tweet]
Kimi K2-0905 update
- Enhanced coding capabilities, esp. front-end & tool-calling
- Context length extended to 256k tokens
- Improved integration with various agent scaffolds (e.g., Claude Code, Roo Code, etc)
Weights & code: huggingface.co/moonshotai/Ki… Chat with new Kimi K2 on: kimi.com️ For 60–100 TPS + guaranteed 100% tool-call accuracy, try our turbo API: platform.moonshot.ai
6/7
@AIfeedFyi
5. Alibaba rolls out Qwen3-Max-Preview.
→ Biggest model yet, with over 1 trillion parameters.
→ Better in reasoning, code generation, and conversation over past Qwen releases.
[Quoted tweet]
Big news: Introducing Qwen3-Max-Preview (Instruct) — our biggest model yet, with over 1 trillion parameters!
Now available via Qwen Chat & Alibaba Cloud API.
Benchmarks show it beats our previous best, Qwen3-235B-A22B-2507. Internal tests + early user feedback confirm: stronger performance, broader knowledge, better at conversations, agentic tasks & instruction following.
Scaling works — and the official release will surprise you even more. Stay tuned!
Qwen Chat: chat.qwen.ai/
Alibaba Cloud API: modelstudio.console.alibabac…
7/7
@AIfeedFyi
Explore http://aifeed.fyi and follow us @AIfeedFyi for full AI signals, breakdowns, and everything happening in AI right now.
/search?q=#AIfeed
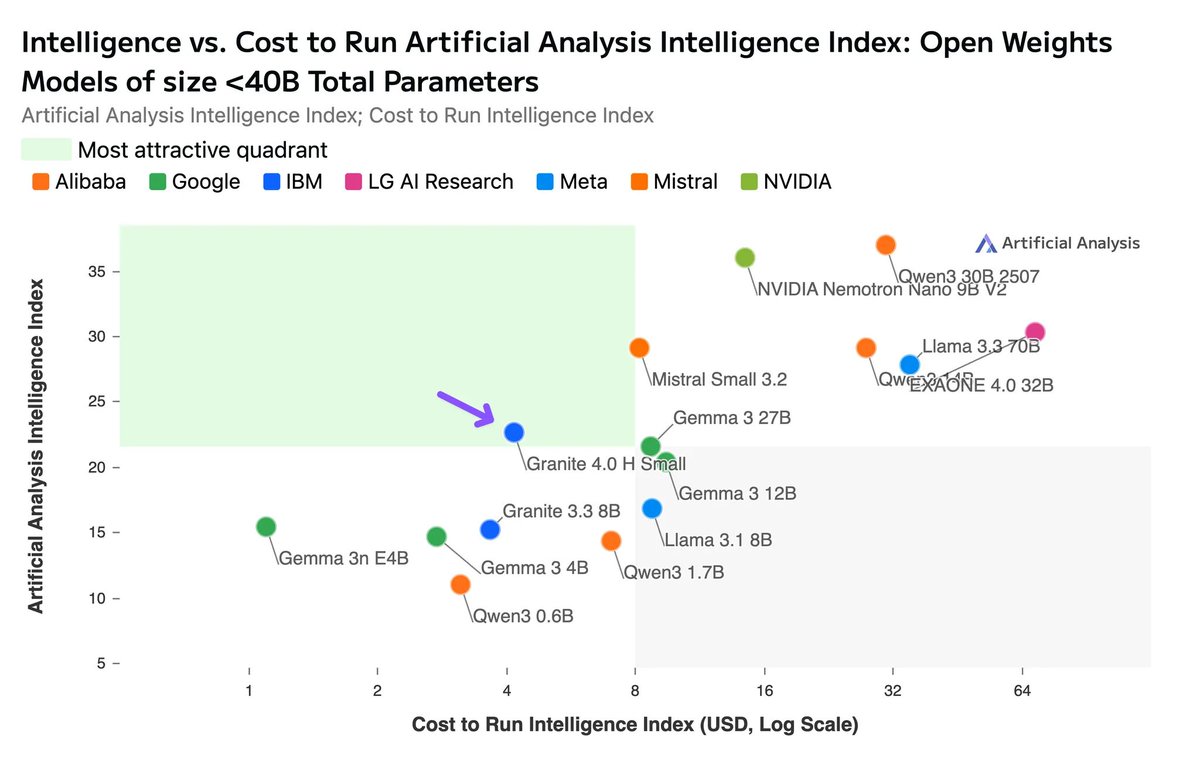
 Granite 4.0 H Small Intelligence: In non-reasoning, Granite 4.0 H Small scores 23 on the Artificial Analysis Intelligence index - a jump of +8 points on the Index compared to IBM Granite 3.3 8B (Non Reasoning). Granite 4.0 H Small places ahead of Gemma 3 27B (22) but behind Mistral Small 3.2 (29), EXAONE 4.0 32B (Non-Reasoning, 30) and Qwen3 30B A3B 2507 (Non-Reasoning, 37) in intelligence
Granite 4.0 H Small Intelligence: In non-reasoning, Granite 4.0 H Small scores 23 on the Artificial Analysis Intelligence index - a jump of +8 points on the Index compared to IBM Granite 3.3 8B (Non Reasoning). Granite 4.0 H Small places ahead of Gemma 3 27B (22) but behind Mistral Small 3.2 (29), EXAONE 4.0 32B (Non-Reasoning, 30) and Qwen3 30B A3B 2507 (Non-Reasoning, 37) in intelligence Token efficiency: Granite 4.0 H Small and Micro demonstrate impressive token efficiency - Granite 4.0 Small uses 5.2M, while Granite 4.0 Micro uses 6.7M tokens to run the Artificial Analysis Intelligence Index. Both models fewer tokens than Granite 3.3 8B (Non-Reasoning) and most other open weights non-reasoning models smaller than 40B total parameters (except Qwen3 0.6B which uses 1.9M output tokens)
Token efficiency: Granite 4.0 H Small and Micro demonstrate impressive token efficiency - Granite 4.0 Small uses 5.2M, while Granite 4.0 Micro uses 6.7M tokens to run the Artificial Analysis Intelligence Index. Both models fewer tokens than Granite 3.3 8B (Non-Reasoning) and most other open weights non-reasoning models smaller than 40B total parameters (except Qwen3 0.6B which uses 1.9M output tokens) Availability: All four models are available on Hugging Face. Granite 4.0 H Small is available on Replicate and is priced at $0.06/$0.25 per 1M input/output tokens
Availability: All four models are available on Hugging Face. Granite 4.0 H Small is available on Replicate and is priced at $0.06/$0.25 per 1M input/output tokens Context Window: 128K tokens
Context Window: 128K tokens Licensing: The Granite 4.0 models are available under the Apache 2.0 license
Licensing: The Granite 4.0 models are available under the Apache 2.0 license












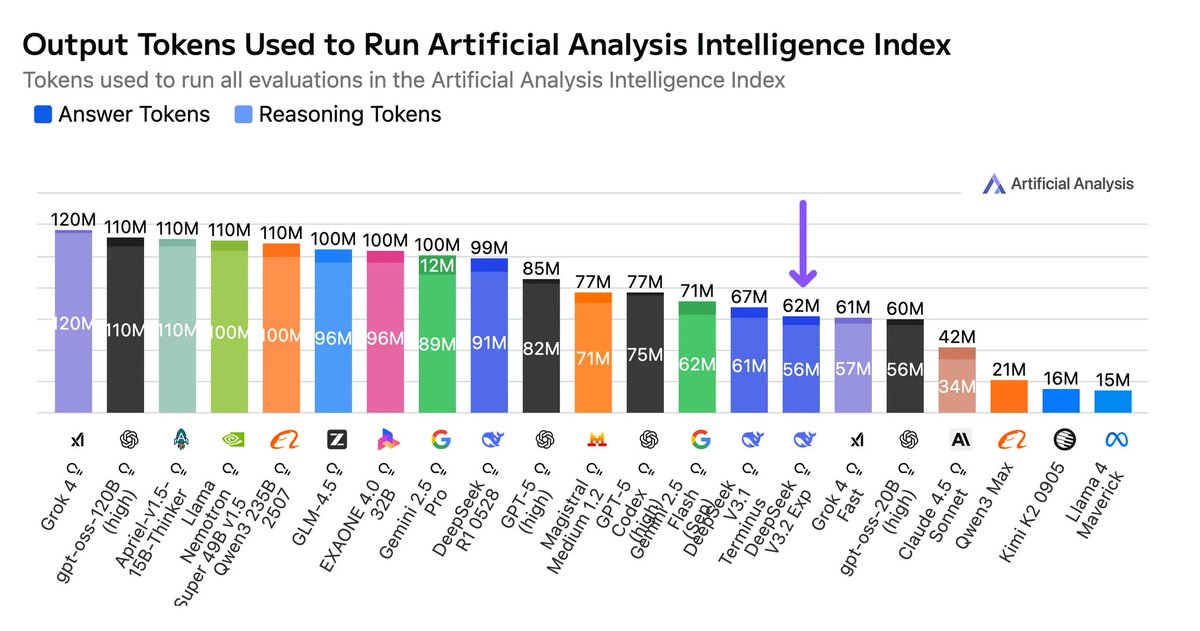
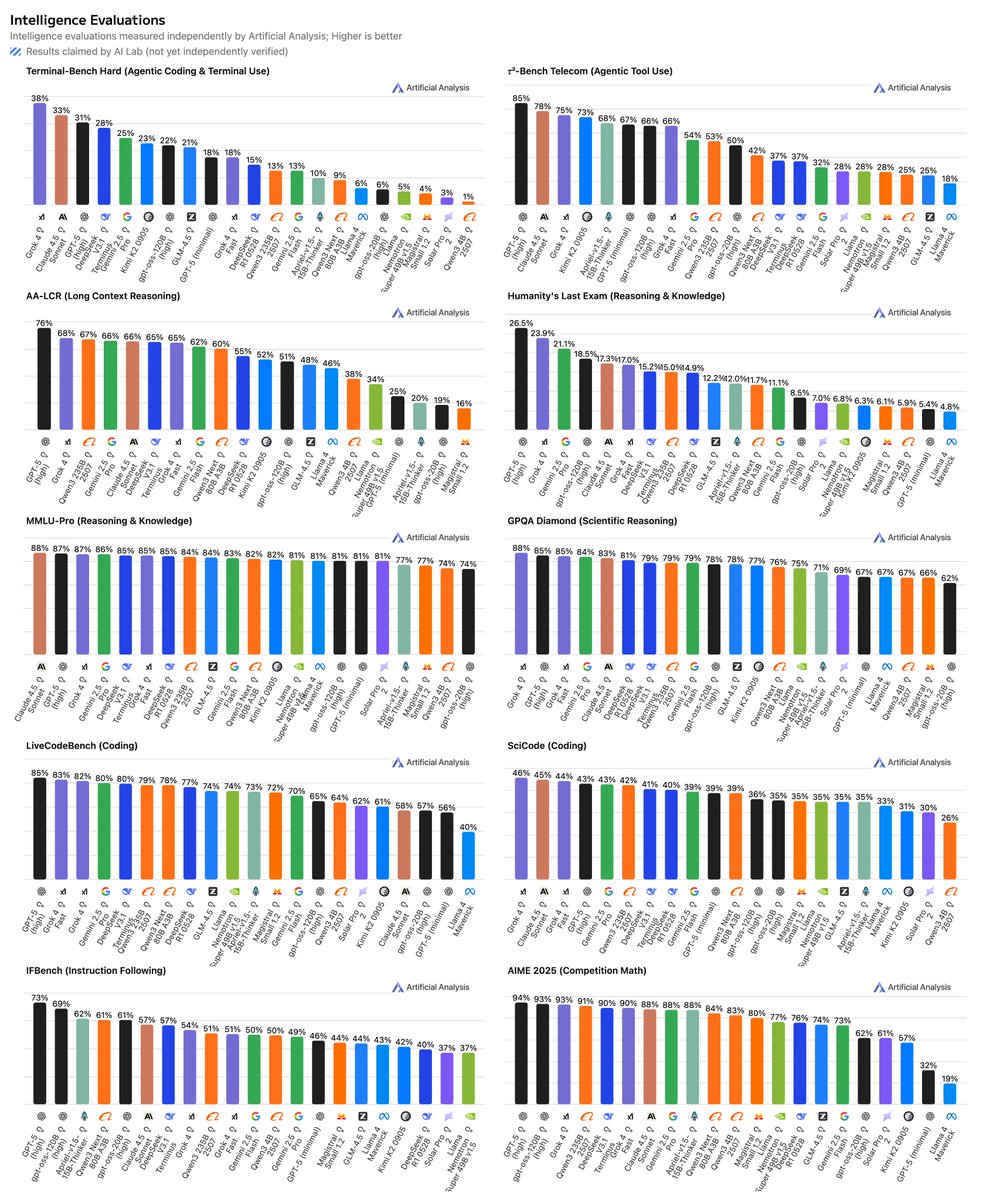
 No decline in long context reasoning: Despite DeepSeek’s architecture changes, V3.2 Exp (Reasoning) appears not to exhibit any decline in long context reasoning - scoring a slight uplift in AA-LCR.
No decline in long context reasoning: Despite DeepSeek’s architecture changes, V3.2 Exp (Reasoning) appears not to exhibit any decline in long context reasoning - scoring a slight uplift in AA-LCR. Pricing: DeepSeek has significantly reduced the per token pricing for their first-party API from $0.56/$1.68 to $0.28/$0.42 per 1M input/output tokens - a 50% and 75% reduction in pricing of input and output tokens respectively.
Pricing: DeepSeek has significantly reduced the per token pricing for their first-party API from $0.56/$1.68 to $0.28/$0.42 per 1M input/output tokens - a 50% and 75% reduction in pricing of input and output tokens respectively.



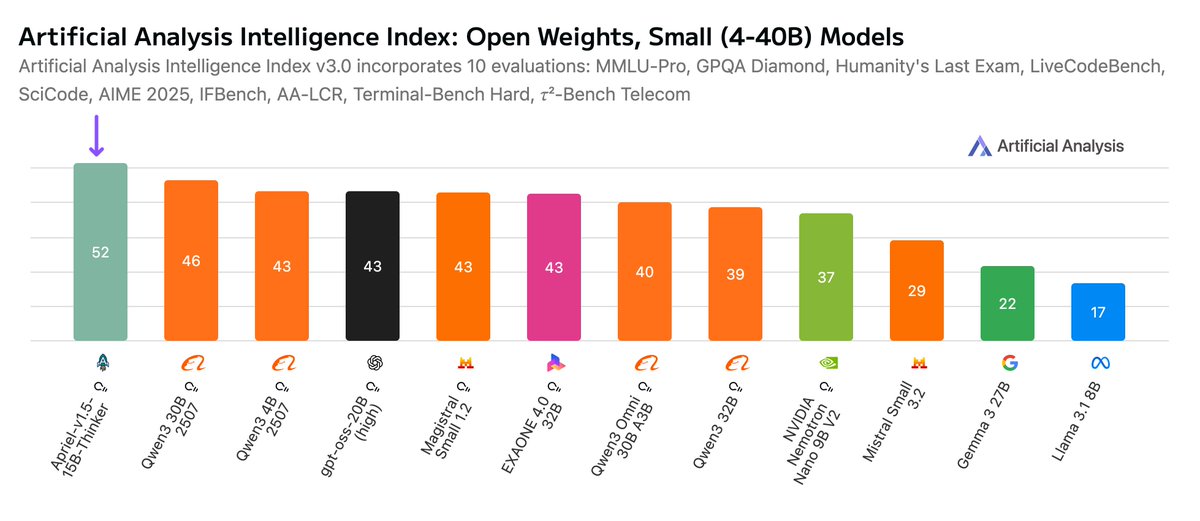
 Overview: Apriel-v1.5-15B-Thinker is a dense, 15B parameter open weights reasoning model. This is not the first model ServiceNow has released but is a substantial jump in intelligence achieved compared to past releases
Overview: Apriel-v1.5-15B-Thinker is a dense, 15B parameter open weights reasoning model. This is not the first model ServiceNow has released but is a substantial jump in intelligence achieved compared to past releases Access: No serverless inference providers are yet serving the model, but it is available now on Hugging Face for local inference or self-deployment. The model has been released under an MIT license, supporting unrestricted commercial use
Access: No serverless inference providers are yet serving the model, but it is available now on Hugging Face for local inference or self-deployment. The model has been released under an MIT license, supporting unrestricted commercial use Context window: The model has a native context window of 128k tokens.
Context window: The model has a native context window of 128k tokens.


 HuggingFace repo:
HuggingFace repo: 


 Proprietary: Like the Preview version, Qwen3 Max is proprietary, since Alibaba has not released the weights.
Proprietary: Like the Preview version, Qwen3 Max is proprietary, since Alibaba has not released the weights. Multimodality: Qwen3 Max is text-only, with no multimodal inputs or outputs.
Multimodality: Qwen3 Max is text-only, with no multimodal inputs or outputs.

 Max output tokens: 64K tokens
Max output tokens: 64K tokens

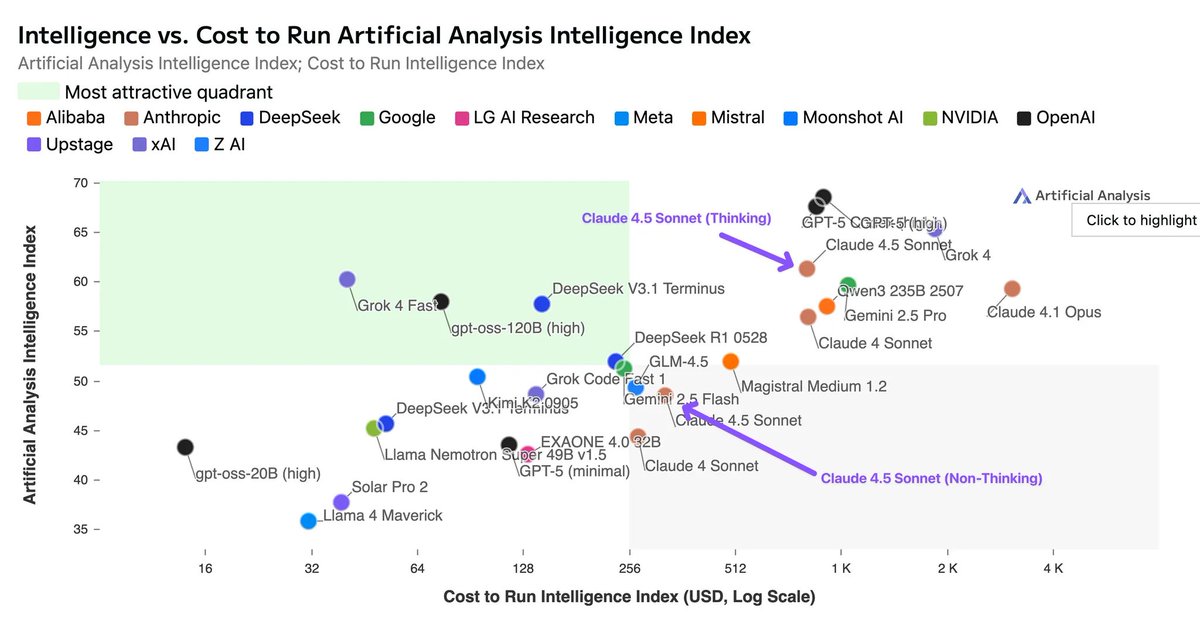











 How much faster is it, though?
How much faster is it, though?





 What specific features do you think set HunyuanImage 2.1 apart? I'd love to hear your thoughts!
What specific features do you think set HunyuanImage 2.1 apart? I'd love to hear your thoughts!


